.svg)

Onur Yürüten
Head of Age Assurance Solutions, Privately SA
There is a drive to make the internet age-aware, and secure compliance from platforms and businesses with laws recently enacted by the Australian Parliament, the KOSA in the USA and OSA (Online Safety Act — UK) which comes into force in January 2025. A wide range of platforms and businesses with age-sensitive products, goods or services will need to demonstrate that they have taken reasonable steps to protect children online and automated age estimation has emerged as a key technology to fulfill this requirement
AI-based age estimation solutions can detect underage users, and thus enable businesses to deliver age-appropriate experience to these customers and further meet policies for safe user engagement. These solutions typically scan the face or voice of the users and feed this data to machine learning models that make an age prediction. Sudden demand has spawned many fly-by-night operators who claim to have solutions but which would really not hold up to deeper testing and scrutiny.
As a buyer of Age Estimation systems it’s important to understand the right metrics in order to correctly evaluate age estimation systems. In the first in this series of posts, we explore recall, which we believe to be a core metric for tracking model performance.
Recall: the metric that matters
Accuracy is a commonly used metric for evaluating machine learning models, but it can be misleading in certain situations, particularly when dealing with imbalanced datasets. In age estimation, underage users (e.g. users under the age of 13, depending on jurisdiction) may be relatively rare compared to older users, making them a minority class. In such cases, a model could achieve high accuracy by simply predicting that all users are above the age threshold, since that would often be the most frequent outcome. However, this would completely overlook the underage users, which is exactly the population the regulation is most concerned with.
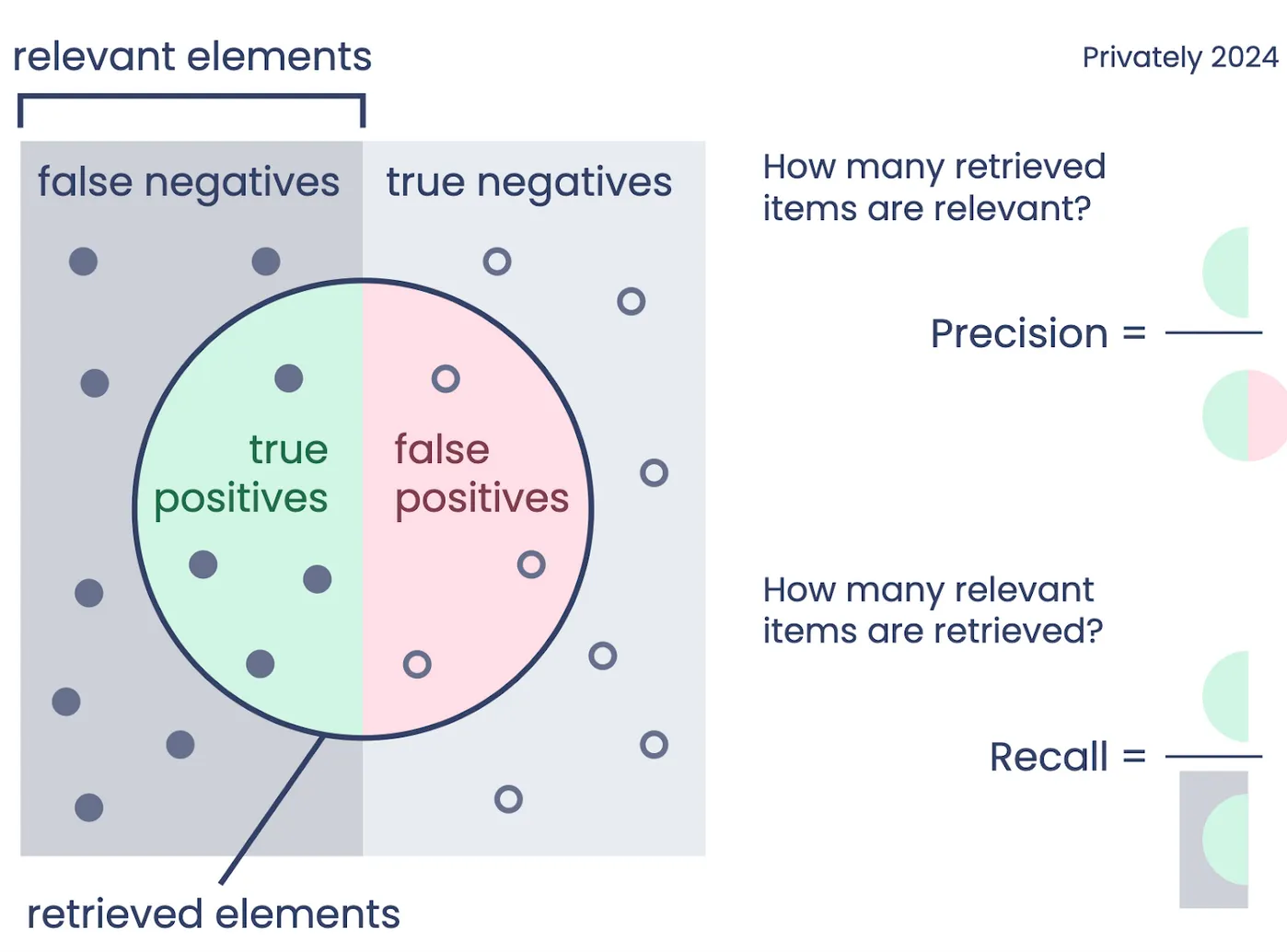
Recall is the ability of a model to identify all relevant instances within a dataset — in the case of age estimation, recall helps answer the critical question: Of all the users who should have been flagged as underage, how many did the model catch?
The formula for recall is:
Recall = (TruePositives)/(TruePositives+ False Negatives)
Where:
- True Positives are the correctly identified underage users.
- False Negatives are the underage users the model failed to identify.
Regulation adds context to Recall
Recall is not a static number — it depends on the chosen age threshold. This threshold, or the age cutoff point that defines “underage”, may be dictated by local laws and regulations. For instance, in some regions, an underage user may be defined as anyone under 13, while in others, the threshold could be higher, such as under 16 or under 18. The Challenge 25 (UK) policy adds another important layer to the discussion about age verification, especially in contexts where businesses are looking to identify underage users. The Challenge 25 principle, widely used in industries like retail and hospitality, suggests that if a person appears to be under the age of 25, they should be asked to provide ID documents to verify their age. Another notable threshold is the age of 16 that is defined in the recent Australian legislation for social media access.
In this context, businesses must carefully consider the legal requirements in each market they serve, adjusting the threshold for age classification to reflect local laws and regulations.
Balancing Recall with Other Metrics
There are of course other metrics to measure the quality of an age estimation system, and each metric may help you address a separate business objective, such as:
- Reducing Customer Friction: How easy is it for your adult users to pass age check with success? Along with a great UX design, a model with a good precision score can ensure you fulfil this objective. We will cover precision in a subsequent post.
- Respecting data privacy: Privacy is another critical concern when dealing with sensitive user data, especially minors. If your age estimation process runs completely on the user’s device, then you can ensure that no personal information would ever need to leave, strengthening your posture on privacy considerations. Here, the model size might be an important metric to track — the smaller it is, the easier it will be to deploy the solution on various devices, apps, and browsers.
External Age Estimation Solutions: Trust but Verify
Your company may not have the resources or expertise to develop their own in-house age estimation models but that’s OK — there are a variety of third-party solutions available.
When evaluating such solutions, you should request the tech supplier to demonstrate independent third-party certifications for both accuracy and privacy. In this way, you can ensure that you remain compliant and ethically responsible in your use of age estimation technologies. For instance, Privately has put up its age estimation for scrutiny by ACCS, an ISO and UKAS certified independent conformity assessment body, and obtained essential accuracy and data privacy certifications: https://accscheme.com/registry/age-assurance/privately-sa/ .
Where public certifications are not (yet) available (for example for <18s), the provider should be able to show such recall on neutral datasets that they have not trained on. As an example, Privately’s internal assessments indicate:
- A 99.97% recall rate for 6–12 year olds against the 16 age gate.
- A 99.61% recall rate for 13–17 year olds against the 24 age gate.
Conclusion
When selecting the most suitable age estimation solution, Recall provides a clear picture of how well the model performs for the objective that matters the most: minimising the risk of missing minors in critical scenarios.
Additionally, for businesses that choose to partner with external vendors for age estimation solutions, they should ensure that these vendors have the right certifications for both accuracy and privacy. This way, they will have a peace of mind and further mitigate risk.
In the end, it’s not just about building accurate models — it’s about building responsible models that align with both legal requirements and the broader social responsibility to protect children online.




